
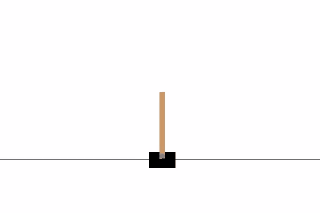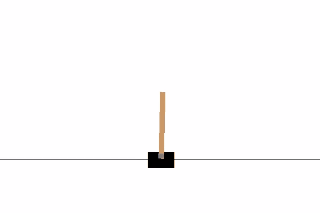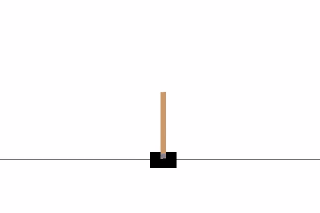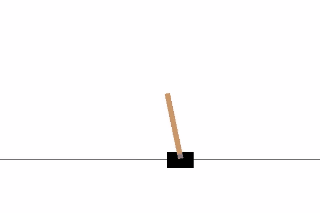
This blog post will demonstrate how deep reinforcement learning (deep Q-learning) can be implemented and applied to play a CartPole game using Keras and Gym, in less than 100 lines of code!
I’ll explain everything without requiring any prerequisite knowledge about reinforcement learning.
